Build Your Own AI Gaming Mate Part 0: Overview
Introduction
I wanted a local AI gaming mate that could watch my gameplay, react to what is happening, and talk with me like a friend sitting beside me. Not as a benchmark demo, but as something I could actually use while playing games.
The system I ended up with looks like this:
- OBS pushes my gameplay stream over WebRTC.
- MediaMTX receives and serves the stream locally.
- OpenClaw attaches to my Chrome session and watches the game stream there.
- Discord gives me a simple interaction channel that works well during play.
- I use macOS speech-to-text and a 3-key deck pedal so I can keep my hands on keyboard, mouse, or controller.
- For voice replies, I can use built-in or hosted TTS, and I optionally self-host Qwen3-TTS with
mlx-audiowhen I want more control over the voice. - A tuned set of interactive and agent skills keeps the whole loop responsive and fun.
The result is a companion that watches the game, reacts in real time, and feels closer to a friend on the couch than a generic assistant.
This post is the overview for the whole series. The goal here is to show what the system does, why each piece exists, and how the parts fit together.
What “Gaming Mate” Means Here
I am not trying to build an esports coach, an autonomous streamer, or a general desktop agent. The goal is narrower and more practical:
- Watch the game I am currently playing.
- Keep enough context to comment on what is happening.
- React quickly enough to feel present.
- Let me talk naturally without breaking the flow of the game.
- Keep the core loop local so I have tighter control over latency, privacy, and behavior, while still leaving room for hosted pieces when they are convenient.
That last point matters a lot. For this kind of companion experience, “local” is not just about privacy. It is also about reducing friction. If the loop is too slow, too brittle, or too dependent on remote services, it stops feeling like a mate and starts feeling like a delayed voice assistant.
Demo
This screenshot captures the kind of interaction I wanted:
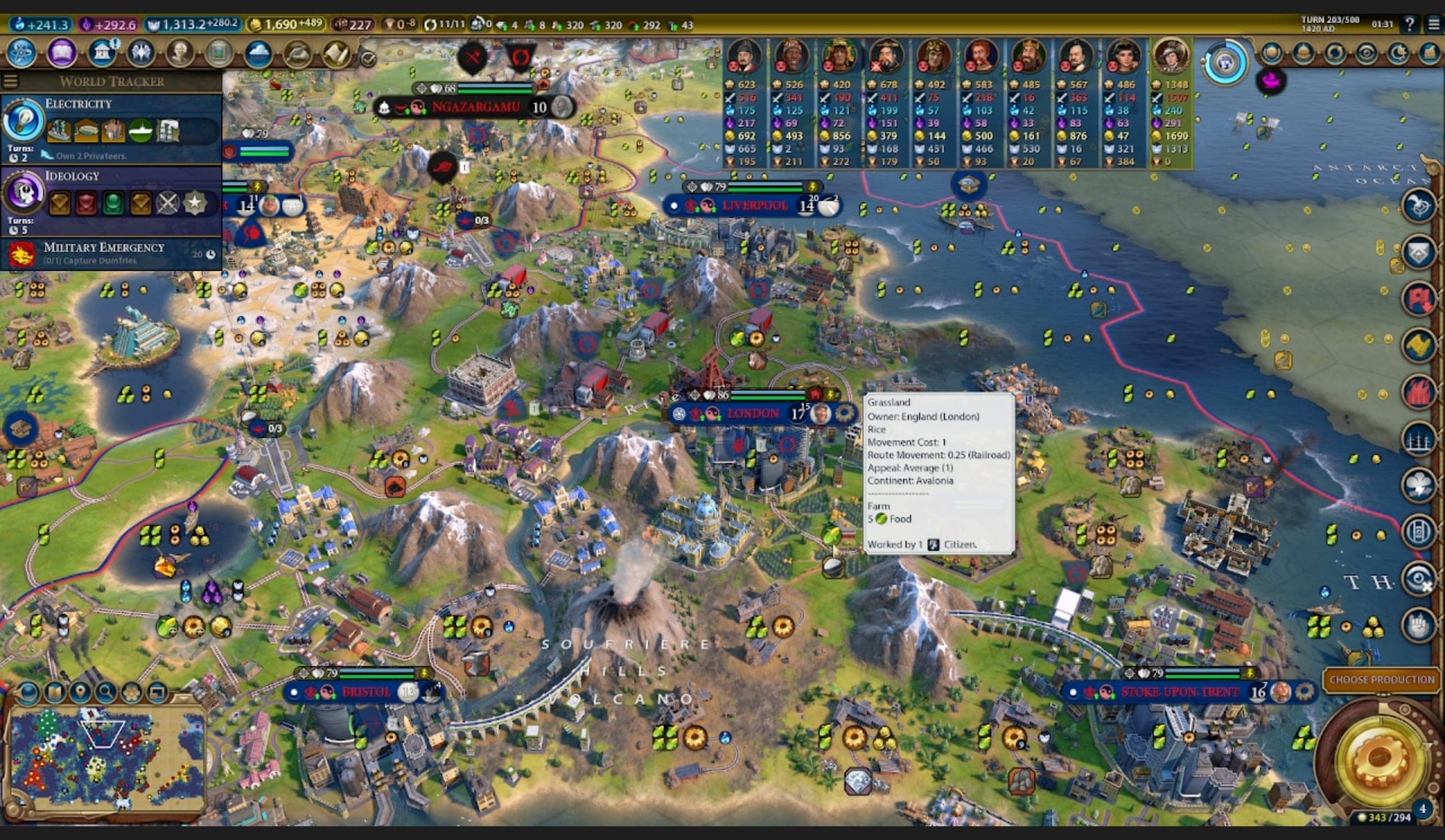
A gameplay exchange where the mate revises its judgment as soon as I provide better numbers.
In this session, I loaded a later Civilization VI save and asked the mate to reassess my position. The first answer was based on what it could infer from the frame. Then I sent the exact numbers, and it immediately updated the judgment. That kind of fast conversational course correction is the whole point of the project.
The first estimate is approximate by design because it is inferred from the screen rather than pulled directly from structured game data. What I care about is that the mate can revise quickly once I give it better information, just like a real conversation would.
Me: I loaded a save from a later point in the game. Re-evaluate my civilization’s position.
Gaming mate: Let me look at this new save frame first. It is much clearer this time: you are no longer just in the upper-middle of the pack. You are firmly in the top tier, and very likely one of the strongest civilizations overall. This is already a strong late-game position built on culture and science, with enough military power to stay safe. The real question is not whether you can win, but how you want to close the game out.
Me: Let me give you the correct numbers instead: military 1507, science 240, culture 291, gold 1690, faith 1313.
Gaming mate: Then it is very clear: you are not just one of the top-tier civilizations. You are basically the dominant power on the map. This is a fully snowballed late-game position. Unless you choose the wrong victory route or intentionally drag it out, you have already moved from “a contender” to “everyone else needs a plan to stop you.”
End-to-End Architecture
At a high level, the flow looks like this:
Game
-> OBS
-> WebRTC
-> MediaMTX
-> Chrome tab
-> OpenClaw
-> local agent logic and skills
-> response
Speech input
-> deck pedal shortcut
-> macOS speech-to-text
-> Discord message
-> local agent logic and skills
-> text response
Voice output
-> system TTS, online TTS, or Qwen3-TTS via mlx-audio
-> spoken reply
Each piece exists for a reason:
- OBS gives me a stable way to capture gameplay.
- MediaMTX gives me a local streaming endpoint that is easy to control.
- Chrome gives OpenClaw a browser session it can observe reliably.
- Discord gives me a simple interaction transport for the loop.
- macOS speech-to-text lets me talk without building a custom speech input UI first.
- Built-in or hosted TTS can cover basic voice output.
- Qwen3-TTS and
mlx-audiogive me a self-hosted path when I want more control over voice quality and personality. - The deck pedal gives me hands-free shortcut control during gameplay.
Why This Combination Works
There are many ways to build something vaguely similar. This combination worked for me because it separates the system into clean layers:
- Video transport
- Browser-visible observation
- Interaction transport
- Voice input and output
- Prompting and skill behavior
That separation makes the system easier to debug. If something feels wrong, I can usually isolate whether the problem is stream delivery, OpenClaw observation, speech input, TTS output, or agent behavior.
Just as important, it let me avoid building too much custom software too early. Discord is not the point of the project. It is a practical transport that let me spend time on interaction quality instead of chat UI. The same applies to voice output: built-in or hosted TTS is enough to prove the experience, while a local Qwen3-TTS setup is the path I use when I want deeper control over the exact voice.
What Makes It Feel Good
The quality bar for this kind of project is different from a normal AI demo. I care less about raw intelligence and more about interaction quality.
The system should feel:
- Fast enough to interrupt naturally
- Short enough to avoid talking over gameplay
- Observant enough to notice obvious events
- Casual enough to feel like company, not a support bot
- Stable enough to use for an actual play session
That is why I spent time tuning the interactive and agent skills. Without that layer, the pipeline works technically but does not feel good to use.
If I had to summarize the product in one sentence, it would be this: it is a conversation system disguised as a gaming tool. Latency, interruption handling, reply length, and tone matter more than showing off a model.
Voice Options
One thing I want to make clear early is that self-hosting TTS is optional. If you do not care much about the exact voice, built-in system TTS or an online provider may be enough.
I use local Qwen3-TTS with mlx-audio for a different reason:
voice is part of the product.
If I am going to hear this companion for hours, I want control over the tone, style, and character of that voice.
That is where a local TTS stack starts to pay off.
So the real tradeoff is not “audio or no audio.” It is convenience versus control. The fast path is to use whatever TTS you already have. The customizable path is to host your own.
Design Constraints
These were the constraints that shaped the system:
- It should work during real gameplay, not only in a staged demo.
- It should not force me to take my hands off the game every time I want to speak.
- It should be easy to restart one broken component without rebuilding the whole session.
- It should stay flexible enough that I can swap the voice path later.
- It should be enjoyable, not just technically impressive.
Those constraints explain some choices that might otherwise look odd, such as using Discord as the interaction transport, macOS dictation as the speech input path, and a deck pedal for shortcut control.
What This Series Will Cover
The rest of the series is split by responsibility:
- Streaming gameplay with OBS, WebRTC, and MediaMTX
- Letting OpenClaw watch the game through Chrome
- Adding voice input, TTS options, and hands-free controls with macOS dictation, Discord, local TTS, and a deck pedal
- Tuning skills, orchestration, and day-2 operations
I am intentionally keeping the posts separate. Trying to explain this as one giant tutorial would make it harder to follow and harder to reuse.
I will keep exact version numbers and detailed setup notes in the implementation posts, where they actually matter. This overview is about the architecture and the product shape.
What I Would Tell Readers Up Front
If you are trying to build this yourself, treat it as a conversation system first and an AI system second. Latency, interruption, and personality matter more than squeezing out one more benchmark point.
Also, get the simplest end-to-end loop working first. Do not start by self-hosting every piece on day one unless you actually need the control. Built-in or online TTS can be enough to validate the experience, and local Qwen3-TTS becomes valuable when you want deeper voice customization.
If the first version already feels responsive and fun, you are on the right track. If it feels smart but slow or awkward, the rest of the stack does not matter yet.
Links
I will update this section as each new post in the series goes live.